Recently, impressive strides have been made in the science of extracting meaning and concepts from images with algorithms. Known as Computer Vision, this science had major concepts formulated in the 80s and 90s. Among them, convolutional neural networks (CNNs), derived from artificial neural networks, were the central element of computer vision. The boom occured when Graphical Processing Units, initially designed for graphics rendering but, in fact, extremely efficient for scientific computing, hit an invisible performance barrier in the 2010s, spawning a myriad of successful recognition tasks. As Andrew Ng, AI pioneer, noted, “A lot of valuable work currently done by humans — examining security video to detect suspicious behaviors, deciding if a car is about to hit a pedestrian, finding and eliminating abusive online posts — can be done in less than one second. These tasks are ripe for automation.”[1]
Artificial Intelligence and Machine Learning

Pablo Picasso, Violin Hanging on the Wall, 1913. Museum of Fine Arts Berne.
If you were given a photo, how would you know that it shows a violin? Something emerges from the picture, and in less than one second, you know. You see shapes, and this collection of shapes means violin to you.
But perhaps you have millions of pictures at hand so you want a computer to help you using classical programming. In the symbolic AI paradigm or “rules-based” programming, computer scientists make the rules that determine what is a violin, and a computer then routinely checks the data against these set rules to make decisions. If the rules are smart and robust you get accurate results. But it turns out our human rules can be hard to translate in machine terms.
This is where machine learning comes into play. Can we let computers decide the rules by themselves? After all, we have the pictures (data) and we have the labels (answers). We just have to devise the computational structures to let them learn.

Two different approaches: symbolic AI, above, and machine learning, below (Francois Chollet, Deep Learning with R (Shelter Island, NY: Mannning Publication, 2018).
Convolution and Neural Networks
In 2006, Dr. Fe-Fei Li, a professor at Stanford University, started assembling millions of images in a database: thousands of pictures each of kites, Chihuahuas, cassette players, or really any subject imaginable.[2] Four years later, in a competition to determine how well algorithms could classify these pictures, the best attempt claimed a 49% error rate.
At the time, computer vision scientists broke down the task in two different steps:
1. Feature engineering: reduce/compress the images to keypoints and features (corners, basic shapes, colors..)
2. Train classifier: Feed these features to a machine learning algorithm (bag of words, Fisher vectors..)
The problem, however, is that feature engineering involves choosing what type of feature we think is best for the algorithm. Hence there is a lot of back and forth trying to fine tune step 1 to get the best results in step 2.
In 2012, a team of researchers from Toronto entered the ImageNet Large Scale Visual Recognition Challenge with a Convolutional Neural Network. Inspired by the visual cortex system, CNNs merge the two distinct steps of previous methods in a continuous cascade of neuron layers. The features are engineered by the algorithm itself iteratively and jointly.
They take advantage of two strong assumptions:
1. The visual world is fundamentally translation invariant. Whether a sound hole is at the top or at the bottom of a picture does not change the fact that it is a f-hole.
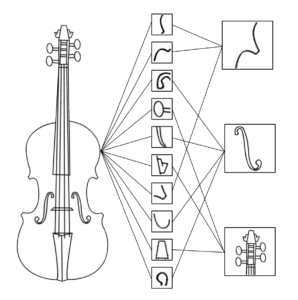
2. The visual world is fundamentally spatially hierarchical. Sound holes are “made of” two lobes, notches and curves. Violins are made of sound holes, bouts etc.

Sound holes are made of two lobes, two notches and curves.
In concrete terms, neural networks are made of stacks of matrices (tables of numbers). These stacks are typically thin and wide at the front of the neural network. As wide as your input pictures, and thick and narrow at the back. Each number in these matrices is called a weight. When you start training a neural net, all these weights are set to different random values between 0 and 1.
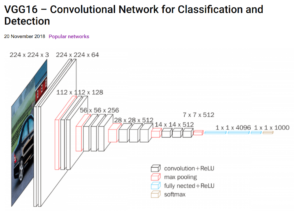
Neural networks are made of stacks of matrices (Neurohive).
During prediction or training, the pixel values of the input image are numbers you multiply against the first stack at the front. The result of the equation is then multiplied against the next layer and so on until it reaches the back of the net. All these operations give one number per class upon which your network predicts. This number is the probability of having the class in the picture according to the network. So if the result is close to 1, the network is pretty sure the class is present in the picture; if it’s closer to 0, it’s pretty sure it’s not.

How information enters the visual cortex system (Haohan Wang and Bhiksha Raj, “On the Origin of Deep Learning,” 2017).
CNNs break down images in a myriad of very small and fundamental features in the first layers. They use the famous deep neural networks of deep learning as a structure and the convolution operation to extract information from the pictures. Further down the layers of neurons, these fundamental features are assembled and transformed into more abstract and higher level features. But how are these features distilled and learned concretely?

Deep representations learned by a digit-classification model (Francois Chollet, Deep Learning with R (Shelter Island, NY: Mannning Publication, 2018).
Neural networks learn features by example in what we call Supervised Learning. It takes three things:
1. Lots of images. These will serve as inputs for the CNN. It will guess what class is in each picture.
2. The actual class present in each image. A human to note the class of each image in order for the machine to learn.
3. A mathematical whip: a loss function + backpropagation. If the CNN’s guess is different from the expected class, we measure this error and, through calculus, we propagate tweaks from the back of the CNN to the front. These tweaks adjust the values of the weights.
When CNNs appeared, they required so much data and computational power to learn useful representations that they weren’t receiving much attention. But as computing power skyrocketed and data warehouses grew immense, they started to make a difference in image classification and object detection tasks. The Toronto team used another model resulting in a 36.7% error rate. The next year, most teams used CNNs. Today, the EfficientNet-L2 scores below 10% error rate.
Object Detection at Tarisio and Transfer Learning
The term object detection is commonly used to refer to the task of naming and localizing multiple objects in an image frame.[3] There are three levels of object detection:
Object classification: labeling each photo
Object localization: drawing a bounding box around objects
Object detection: drawing a bounding box around objects and labelling them
Tarisio challenged me to build a violin parts detector CNN using the hundreds of thousands of pictures in its database. Neural Networks perform best when they get in the hundreds of thousands of training images. For the machine to learn from this data, someone would have to go through and note down the class of each image. The data was there, but who would be crazy enough to annotate all these pictures?

The data was there but who would be crazy enough to annotate all these pictures?
It turns out machine learning is transferable. Once a model has been trained to predict thousands of classes on millions of images, it can be easily tweaked to learn a handful of new classes like sound holes or C-bouts. Because certain types of features are similar enough, and because similar features are found in the middle of the network’s layers, the machine doesn’t need to learn them again. Only the last layers of the network have to be refreshed in a short learning session to learn the new classes, and using much less training data!
While object detection needs slightly more complicated neural network architectures, many of which were developed between 2014 and 2017, the foundational idea of CNN underpins these models.
After painstakingly annotating a thousand images over a few long afternoons and training the model using a decent Graphical Processing Unit, the model tunes itself to our new classes: top, back, head, sound holes and bouts.
Jigsaw solving and self-supervised learning
Another fascinating way (among many) for CNNs to learn useful representations of objects is to make them solve jigsaw puzzles. Try to rearrange 9 shuffle tiles taken from the same picture. Without knowledge of basic violin geometry or flame matching, you would have no chance.

Another way for CNNs to learn useful representations of objects is to make them solve jigsaw puzzles.
As anthropocentric as this technique can appear, behind it lies a real treasure of a training catalyst. Recall that the real bottleneck for training such neural networks is due to the countless hours humans have to spend annotating images before any training can take place. Jigsaw puzzles don’t need annotation. They can be engineered and produced endlessly by a program that randomly selects 9 patches in an image and randomly shuffles them.
These and other techniques gathered under the Self-Supervised Learning label take advantage of the inner regularities of the picture. They could play a major role in the future of machine learning.
Back to symbolic AI
As soon as we began to harvest our first results, the desire to tackle a more violin specific task arose. One of the classes the detector is good at is identifying back bodies. Now can we build a program that can establish if a back is made of one or two pieces of wood, given one of these back body crops detected by STRIP?

One and two piece backs.
It turns out really good results can be obtained with a succession of automated steps:
1. Extract patches from the image along the center seam
2. Apply some carefully attuned image filtering to enhance the flames
3. Turn the patches into a set of curvy lines running along the flames with a clever classical algorithm
4. Fit a (straight) line on every of these lines
5. Given the directions and the centers of these straight lines, the machine checks if they fall into two distinct groups, one on the left and one on the right with each its own but distinct homogeneous direction. If they do, we have a two piece back.

The original image and Steps 1-4.
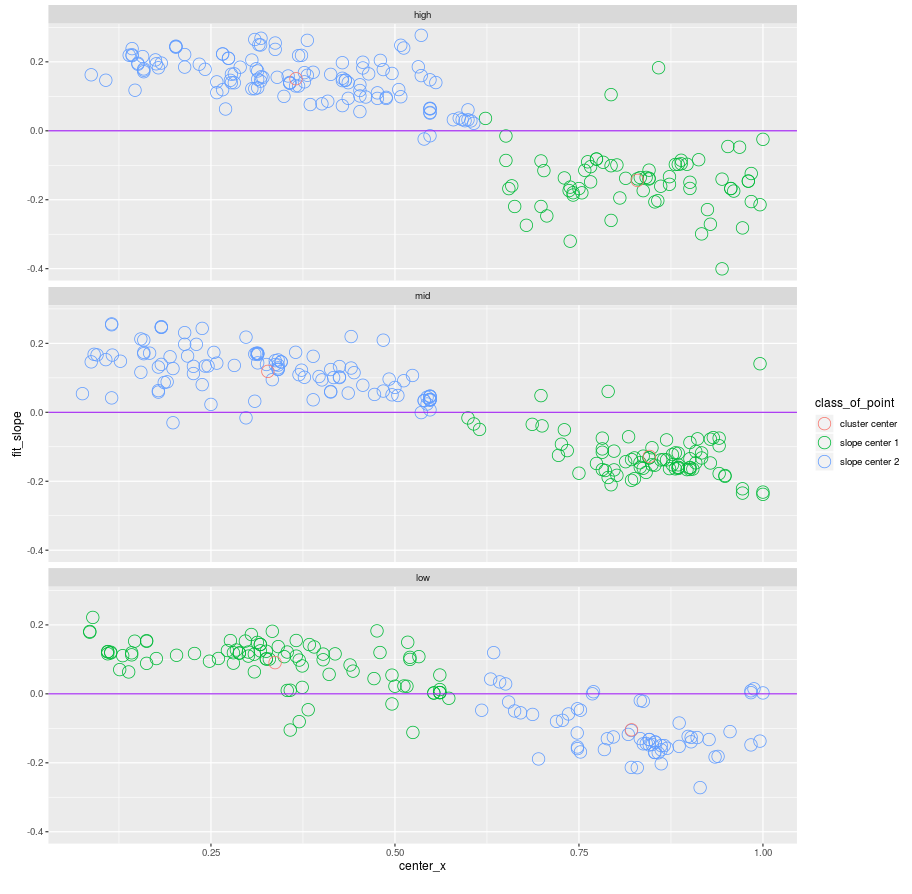
Step 5: As a bonus, we get a robust estimate of the direction of the flames in each part.
What’s Next?
Being able to accurately extract violin parts from images opens the door to many further developments. One of them already showing promise is the one-piece vs. two-piece back recognition and flame orientation estimation. These two metrics could be part of a larger idea: fingerprinting violins. Future experiments will focus on classifying the position, angle and frequency of flames and mapping knots and pins.
From reading handwritten digits on cheques to predicting the 3D structure of massive proteins, computers are now able to take on a variety of tasks and improvements in the field of Artificial Intelligence have surprised many over the last 20 years. Beyond the flashy headlines, Machine Learning offers new tools for industries running data intensive processes. Not only does this novel approach change how data is interacted with, it can also transform perspectives regarding the content itself.
Benoît Fayolle is a Data Engineer in the energy industry and Computer Vision practitioner
Notes
[1] Andrew Ng, “What Artificial Intelligence Can and Can’t Do Right Now,” Harvard Business Review, November 9, 2016, https://hbr.org/2016/11/what-artificial-intelligence-can-and-cant-do-right-now.
[2] John Markoff, “Seeking a Better Way to Find Web Images,” New York Times, November 19, 2012, https://www.nytimes.com/2012/11/20/science/for-web-images-creating-new-technology-to-seek-and-find.html.
[3] Sigrid Keydana, “Naming and locating objects in images,” RStudio, November 5, 2018, https://blogs.rstudio.com/ai/posts/2018-11-05-naming-locating-objects/